It’s the harness, not the model
Date
Reading time
9 minutes
Author
Ivan Traus, Liminary Engineering

In our last post we introduced Liminary's AI-native storage and showed that it answers questions about a real document corpus more accurately, and faster, than a general-purpose chatbot pointed at the same files in Google Drive. That post was about the bottom half of the system — how we store and index your sources so a model can find what it needs. (Methodology recap: 100 short-answer questions built from real customer-research interviews, scored partial-credit on list questions; details in the last post.)
This post is about the harness around the model — the prompts, tools, memory, and routing that turn a frontier LLM into a system that can reliably answer questions about a real document library. When you ask Liminary something, what looks from the outside like one assistant thinking hard is, under the hood, a small group of specialized agents collaborating. Getting that team to work well taught us more than getting any single agent to work well.
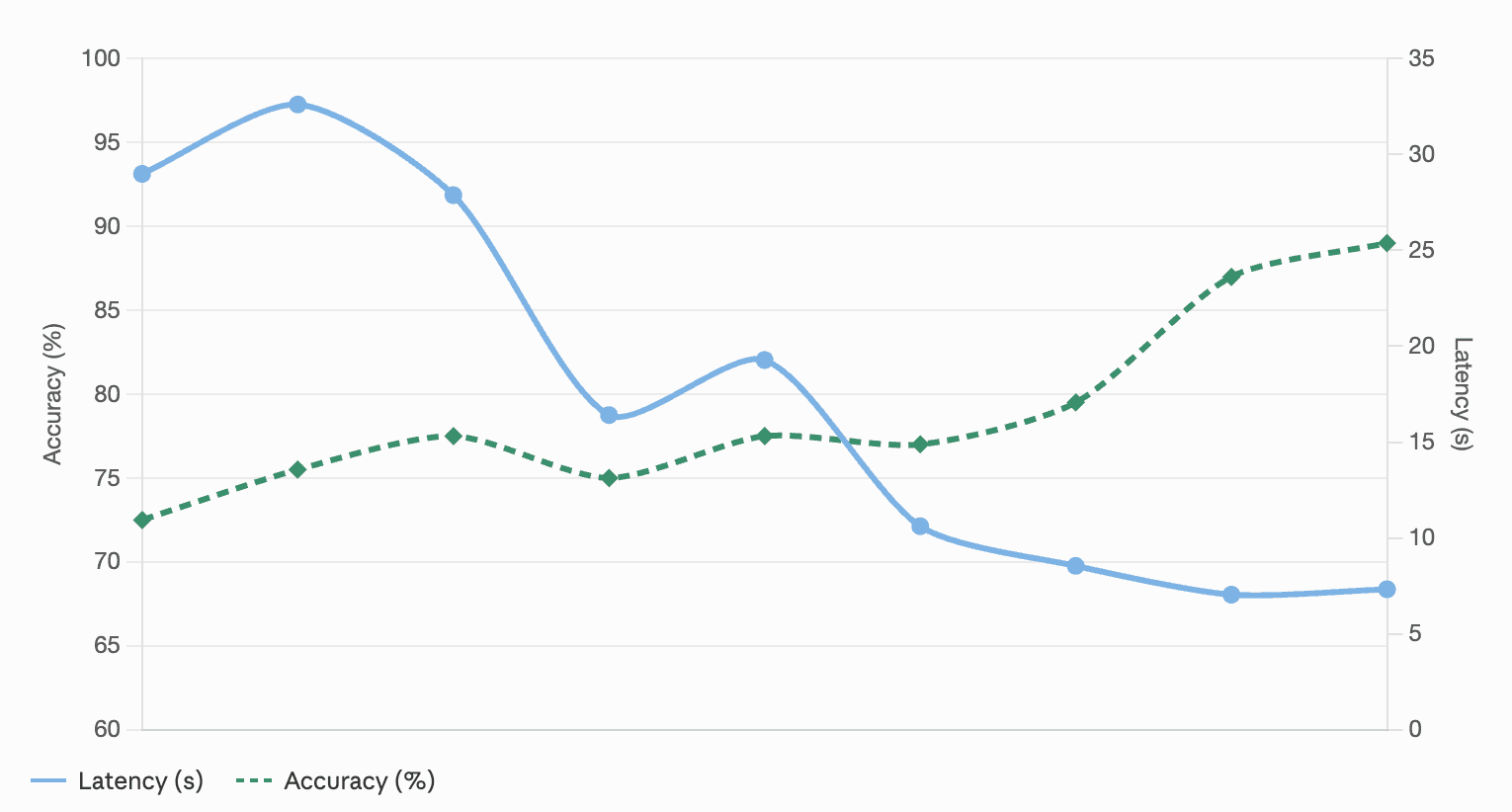
The biggest gains we measured on our internal benchmark didn't come from a smarter model. They came from a better harness around it. Compared to our first agentic prototype — one model, one enormous system prompt, a long list of overlapping tools — our current pipeline is roughly 18% more accurate and answers in less than a quarter of the time. Almost none of that came from a single trick. It came from getting seven unglamorous things about the harness
Accuracy and latency over iterations of the system
1. Specialize: one agent is rarely the right answer
The first and most important shift was recognizing that "answer the user's question about their library" isn't one job. It's at least three:
Plan and orchestrate. Decide what the user is really asking, figure out which sources are worth looking at, dispatch work, and decide when there's enough information to answer. Wants a strong instruction-following model; mistakes here are expensive because every downstream step inherits them.
Read a source carefully. Given a single document or web page, pull out the parts that bear on the question. Wants a fast model with a very long context window (we want to read the whole document, not a paragraph at a time), and a narrow job description so it doesn't get creative.
Synthesize the final answer. Look at everything that was gathered, reconcile contradictions, pick which sources to cite, and write the response. Wants a stronger reasoner with a generous thinking budget — this is the step where getting the nuance right matters most.
We used to have one model try to do all three. Now each role is a separate LLM invocation with its own prompt and model, dispatched by the orchestrator through the same tool-use interface it uses for everything else (see ReAct, https://arxiv.org/abs/2210.03629; Toolformer, https://arxiv.org/abs/2302.04761).
Two non-obvious wins came from this:
Different models for different jobs. The read-a-source step is a huge fraction of total work on any multi-document question. Moving that step to a fast long-context model, while keeping the stronger reasoner for synthesis, was the single biggest lever we pulled on cost and latency. You pay for the premium model only where it materially changes the answer.
Parallelism. Because each reading step is an independent tool call, the orchestrator can dispatch several of them in a single turn — reading five sources at once rather than one after another. Modern tool-use APIs support this out of the box, and we lean on it hard — a meaningful share of the roughly 75% latency reduction we’ve seen since our single-agent days.
2. Shrink the orchestrator's prompt, and fetch context on demand
Our first orchestrator had a long system prompt. It had to — it listed every capability of the product, described what the user was currently looking at, enumerated the documents in their current collection, and laid out rules for each of the dozen-or-so tools it might call. Every turn, the model re-read all of it.
Over time, most of that got deleted from the prompt. Not because we dropped features, but because almost all of it was better delivered as a tool response on demand rather than as static context up front.
The list of documents in your current collection? The orchestrator doesn't need it to answer "what time did my last meeting start." It only needs it when scope matters. So we made it a tool call.
Product capabilities? Same — they matter to a fraction of questions. Now the orchestrator can fetch them when it needs them.
The current document or selection you're focused on? Same story.
The principle: front-loaded context pushes the model's attention toward static background and away from the current question. On-demand context lets the model decide where to spend attention — a dynamic that compounds with the well-documented positional-attention biases in long-context LLMs (Liu et al., “Lost in the Middle,” https://arxiv.org/abs/2307.03172). A smaller prompt also means faster inference. On our benchmark, moving the collection-document list alone out of the prompt and behind a tool call lifted partial-credit accuracy by about 3%, with no other change in the system.
3. Tool hygiene: don’t repeat yourself, name things well
Agentic systems accumulate duplicated instructions the way old codebases accumulate duplicated constants. A rule for how to cite a source, written once in the system prompt and again in the description of the tool that writes the answer. Guidance on how to phrase a search query written into the prompt and again into the search tool’s docstring. It feels safe — more reminders, fewer mistakes — but it rots. One copy gets updated, the other doesn’t, and the model starts seeing contradictions it has to reconcile.
We settled on a simple division of labor: the system prompt defines behavior; tool and sub-agent descriptions define how to use that tool or sub-agent. Citation format is a behavior — written once in the system prompt. How to phrase a search query is tool usage — written in the search tool’s description, not the prompt.
We don't have a clean eval number for this one; the win shows up in review time, in how easy it is to change a rule without breaking something else, and in how often the model does something you didn't expect. All of those got better.
Every tool and sub-agent in the system has a name the model sees every time it plans. Those names are the clearest signal to the model about when to reach for a given capability. It's worth spending time on them.
Rough heuristic: names should look like something a non-engineer would say out loud. Verb plus object, plain language, minimal overlap between siblings.
4. Fewer tools, flatter schemas, and merge what always runs together
Three related disciplines, one root cause: every extra option or parameter is another chance for the model to pick the wrong one.
Fewer capabilities. If two tools can do the same job, keep one. The model will occasionally prefer the worse one — and because it returned something, you won't notice until you look.
Flatter input schemas. Nested objects, discriminated unions, and optional-inside-optional structures look elegant in code but generate more tool-use errors than they prevent. Most of our sub-agents today take two to four top-level parameters with obvious types.
Merge steps that always run together. Producing an answer and tagging it with source attribution always ran back-to-back; merging them into one tool call — emit the answer with attribution baked in — removed an entire class of "the model emitted the answer but forgot to attribute it" bugs.
5. Give the system working memory
As the orchestrator dispatches sub-agents and reads sources, we keep a structured running tally of every source that's been examined — not just this turn, but across the whole session. When you ask a follow-up like "tell me more about that third point," the system doesn't need to search again. It already knows what it looked at.
Working memory like this matters more than people expect. It's cheaper and more reliable than trying to reconstruct state from the conversation transcript, and it makes follow-up interactions feel like a conversation rather than a series of fresh starts. It’s also the simplest instance of a much broader research direction around giving LLMs external memory to work around fixed context windows (see MemGPT, Packer et al., 2023, https://arxiv.org/abs/2310.08560).
6. Short, stable IDs for sources
As sources move between sub-agents they need to be referenced — in citations, in follow-ups, in "tell me more about the second one." We assign each source a small auto-incremented ID — a simple counter per resource type, so the first document the system encounters gets one ID, the second gets the next. These are dramatically easier for a model to echo back without corruption than the long opaque keys our database uses internally. When a user clicks, we resolve the short ID back to the real internal identifier server-side; the model never sees or handles the long one. Compact, semantically flat identifiers have been shown to reduce reference-token hallucination in LLMs (see https://aclanthology.org/2024.findings-emnlp.983/), and in practice we saw exactly that: fewer wrong-citation errors and much smoother follow-up questions, where the model has to echo an ID to tell you which source it’s elaborating on.
7. Make the system model-agnostic
One principle we wanted from the beginning: keep the system model-agnostic, so we can always pick the best model for each task and also let our users work with the models they're most comfortable with. Liminary Pro users can choose which frontier model answers their questions, and under the hood we're also free to route different steps of the pipeline — orchestration, reading, synthesis — to whichever model does that particular job best today.
That principle sounds reasonable in the abstract and is surprisingly demanding in practice. The reason comes down to a pattern we walked into accidentally. To move fast, we did most of our prompt iteration against a single model family — running the full cross-family eval only periodically, because it’s slow and expensive. Over time, some prompt changes that scored cleanly on the family we were iterating against regressed on others when we did the sweep. The regressions were small individually but consistent, and they all pointed at the same thing: the same English doesn’t mean the same thing to every model. This kind of prompt fragility across models is increasingly well-studied (see Sclar et al., “Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design,” ICLR 2024, https://arxiv.org/abs/2310.11324); we felt it in the eval.
Our response was to branch the prompt template per model family, so each frontier model gets a version shaped to its priors — same content, different layout, per family. Our primary test matrix today spans GPT 5.x, Claude, and Gemini 3.x, with a few other frontier models we’ve evaluated alongside. Running the same benchmark across every supported backend is how we decide a change is ready to ship: it’s what keeps a prompt improvement for one family from silently becoming a regression for another.
Closing
Stepping back, the pattern across all of this is unexciting: make the next token trivially easy for the model. None of the seven things above are heroic individually; together they’re roughly +18% relative accuracy and a ~75% latency reduction compared to where we started.
We're already chasing the same gains in the other agents we ship — the one that explores the open web, the one you talk to by voice, the one that helps you write documents. Same playbook, same lesson: it’s the harness, not the model. A small team of specialists, each with an obvious job, and a lot of unglamorous engineering around them.
There's still plenty we haven't figured out. More to come.