Benchmarking Update: We Tried Claude Projects and Ask Gemini
Date
Reading time
5 minutes
Author
Thomas Berg, Liminary Engineering

Liminary is 1.4x as accurate as Claude Projects and 1.7x as accurate as Ask Gemini on hard questions in our multi-document question-answering benchmark. And Claude / Gemini are 50-60% slower.
In a recent post, we shared Liminary benchmark results and a comparison with ChatGPT. This time we put Liminary up against Claude Projects from Anthropic and Ask Gemini from Google.
The setup
The dataset, corpus, and scoring are identical to the previous post: 100 hand-written, factual, short-answer questions over a corpus of user research interview notes. See the original post for examples and details.
Claude Projects work a little differently from GPT with the Google Drive connector. Rather than just giving it access to a Google Drive, we have to explicitly add the documents to the project. We created a project, added every document in the corpus, and asked the 100 questions one by one. Opus 4.7 has an "adaptive thinking" option that lets the model spend more time and effort on difficult questions. We ran the benchmark once with the default settings and once with adaptive thinking enabled.
The Gemini chat UI only allows uploading up to ten files, which is not enough for this test. But the Google Drive UI includes an "Ask Gemini" button that lets you ask questions based on a folder in your Drive. This is what we used in our experiments, using a folder (actually a separate Drive) holding only the documents in the corpus.
Results
Here are the results from Liminary, Claude Projects, and Ask Gemini. We also include GPT results from the previous post.
System | Accuracy | Mean latency (sec) |
|---|---|---|
GPT-5.4 (default effort) | 63.0% | 13.8 |
Ask Gemini | 72.7% | 10.9 |
Claude Projects, Opus 4.7 (default) | 77.5% | 11.2 |
Claude Projects, Opus 4.7 (adaptive thinking) | 79.7% | 11.7 |
GPT-5.4 (med effort) with Google Drive | 81.8% | 32.0 |
Liminary | 88.9% | 7.3 |
Accuracy of each system on the benchmark. We give 1 point for each fully correct answer. When the correct answer is a list, we also give partial credit. The final accuracy is the mean over the 100 questions.
Liminary is the fastest and most accurate. We can plot accuracy vs latency to get a sense of how each system behaves. Top (high accuracy) left (low latency) is better.
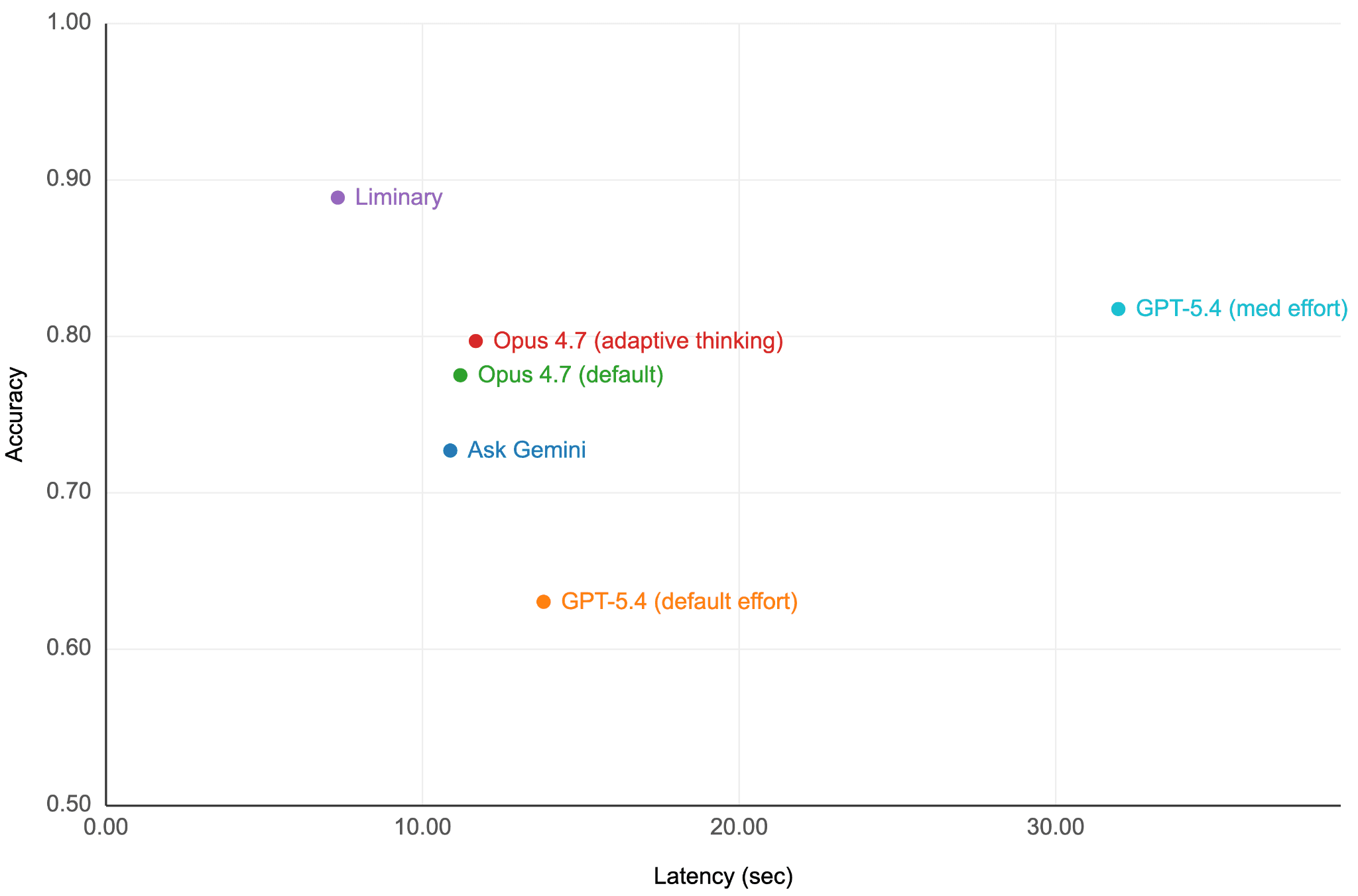
This graph suggests three groups of systems.
Claude Projects and Ask Gemini have similar architectures. In both, you upload the documents for processing before you can ask any questions. We don't know the implementation details, but the Claude Projects documentation suggests they answer questions by passing the entire collection to the LLM if possible, or use search to select relevant documents if the collection is too large to fit in the LLM's context window. This implies building some kind of index. Ask Gemini, as part of Google Drive itself, should have access at least to whatever indexing is done by Google Drive. The three experiments in this set had similar results. Within the set of three results, there's an accuracy-vs-speed tradeoff. They are about 50-60% slower than Liminary and have lower accuracy.
GPT-5.4 shows a large accuracy and latency difference with and without "effort." The architecture is different from the other systems: there is no explicit indexing step. It pays for this in accuracy (it cannot do any index customization) and latency (it has to call out to Google Drive for every search). The only way to get good results with such a system is by doing broad, high-recall, low-precision searches. Although we can only speculate, the "medium effort" version is likely spending its time reviewing initial search results and deciding to fetch more.
Liminary is structurally similar to Claude Projects and Ask Gemini. We pre-process your sources when you save them to make later searches fast, complete, and precise. But our stance as a content-first (not chat-first) platform has led us to develop a proprietary extraction process and carefully tuned agent harness that set us apart. The difference between Liminary and the best result in the Claude Projects / Ask Gemini group is greater than the difference between the best and worst result in that group.
Hard questions
As before, the gap widens on hard questions — the ones that need information from multiple documents, or where the right document can't be found from a keyword in the title. 50 of our 100 questions are answered correctly in the Liminary, Gemini, and both Claude Projects experiments. We call the other 50, where at least one system makes a mistake, "hard" questions. We show accuracy on the hard questions in the table below. Liminary is 1.7 times as accurate as Ask Gemini and 1.4 times as accurate as Claude Projects on these questions.
System | Accuracy |
|---|---|
Ask Gemini | 45.5% |
Claude Projects, Opus 4.7 (default) | 55.1% |
Claude Projects, Opus 4.7 (adaptive thinking) | 59.4% |
Liminary | 77.8% |
Accuracy of each system on hard questions.
Looking through individual questions, we find patterns similar to what we found with GPT. Errors in Ask Gemini and Claude Projects are mostly due to retrieval, either incomplete answers where it has found some but not all of the answers, or outright failures where knowing that a document is relevant depends on more than a simple text match. Liminary's unique ingestion system handles these cases. If these accuracy gains are achievable today not just by scaling compute, but by rethinking how knowledge is ingested and stored before it ever reaches a model, what does that tell us about where the real leverage in AI actually lives? And who owns the value when the bottleneck shifts from the model to the memory layer?
What's next
Having a realistic question-answering benchmark has allowed us to make rapid progress improving our answer quality and latency. We're working on more sophisticated benchmarks to improve Liminary's other capabilities to help you write and edit documents, organize your information, develop your ideas, and more. We'll be sharing more here.